Conceptos importantes de bases de datos
Transacciones
Una transacción de base de datos (transacción de base de datos) es una unidad de trabajo que se completa como una unidad o se cancela como una unidad. El procesamiento adecuado de las transacciones de la base de datos es fundamental para mantener la integridad de sus bases de datos.
Una transacción es una unidad de trabajo lógica y atómica que contiene una o más sentencias SQL.
Una transacción agrupa las sentencias SQL de tal manera que, o bien se comprometen todas, es decir, se aplican a la base de datos, o bien se revierten todas, es decir, se descartan de la base de datos. Oracle Database asigna a cada transacción un identificador único llamado transaction ID.

Todas las transacciones de Oracle están sujetas a las propiedades básicas de las transacciones de la base de datos conocidas como propiedades ACID. ACID es un acrónimo que significa lo siguiente:
Atomicidad
Se ejecutan todas las tareas de una transacción o no se ejecuta ninguna. No hay transacciones parciales. Por ejemplo, si una transacción comienza a actualizar 100 filas, pero el sistema falla después de 20 actualizaciones, la base de datos deshace los cambios en esas 20 filas.
Consistencia
Una transacción mueve la base de datos de un estado consistente a otro estado consistente. Por ejemplo, en una transacción bancaria que cargue una cuenta de ahorros y acredite una cuenta corriente, un fallo no debe hacer que la base de datos acredite sólo una cuenta, lo que daría lugar a datos incoherentes.
Aislamiento
El efecto de una transacción no es visible para otras transacciones hasta que la transacción es confirmada. Por ejemplo, un usuario que actualiza la tabla hr.employees no ve los cambios de empleados no comprometidos realizados en paralelo por otro usuario. De este modo, los usuarios parecen ejecutar las transacciones de forma secuencial.
Durabilidad
Los cambios realizados por las transacciones comprometidas son permanentes. Una vez completada una transacción, la base de datos, a través de mecanismos de recuperación, garantiza que los cambios realizados en la transacción no se pierdan.
El uso de transacciones es una de las diferencias más importantes entre un sistema de gestión de bases de datos y un sistema de archivos.
Concurrencia
La concurrencia de datos es la capacidad de que varios usuarios afecten a varias transacciones en una base de datos. En pocas palabras, la concurrencia de datos permite que varios usuarios accedan a los datos simultáneamente.
La capacidad de proporcionar concurrencia es exclusiva de las bases de datos. Casi todas las bases de datos trabajan con el paralelismo de la misma manera. El principio general es que los datos modificados pero no guardados se almacenan en un registro o archivo temporal. Cuando los datos se guardan, se escriben en el almacén físico de la base de datos en lugar de los datos originales.
Existen dos tipos de concurrencia de bases de datos que se utilizan a diario en las empresas:
Acceso concurrente a los datos - Este tipo de concurrencia es muy importante, ya que se trata de que varios usuarios accedan a los datos simultáneamente sin causar inconsistencias.
Carga de trabajo de consulta compatible - Este tipo de paralelismo es un indicador fundamental del rendimiento del sistema. En los negocios, el término "concurrencia" se utiliza para medir cuántas unidades de trabajo se ejecutan activa y simultáneamente al mismo tiempo.
La concurrencia de la base de datos es la capacidad de una base de datos para permitir que varios usuarios afecten a múltiples transacciones. Esta es una de las principales propiedades que separan una base de datos de otras formas de almacenamiento de datos, como las hojas de cálculo.
La capacidad de ofrecer concurrencia es exclusiva de las bases de datos. Las hojas de cálculo u otros medios de almacenamiento de archivos planos se comparan a menudo con las bases de datos, pero difieren en este importante aspecto.

Las hojas de cálculo no pueden ofrecer a varios usuarios la posibilidad de ver y trabajar con los diferentes datos del mismo archivo, porque una vez que el primer usuario abre el archivo, éste queda bloqueado para los demás usuarios. Los demás usuarios pueden leer el archivo, pero no pueden editar los datos.
Los problemas causados por la concurrencia de la base de datos son incluso más importantes que la capacidad de soportar transacciones concurrentes.
Por ejemplo, cuando un usuario está modificando datos pero aún no los ha guardado (confirmado), la base de datos no debería permitir que otros usuarios que consulten los mismos datos vean los datos modificados y no guardados. En su lugar, el usuario sólo debe ver los datos originales.
Casi todas las bases de datos tratan la concurrencia de la misma manera, aunque la terminología puede diferir. El principio general es que los datos modificados pero no guardados se guardan en algún tipo de registro o archivo temporal.
Una vez guardado, se escribe en el almacenamiento físico de la base de datos en lugar de los datos originales. Mientras el usuario que realiza el cambio no haya guardado los datos, sólo él debería poder ver los datos que está cambiando.
Todos los demás usuarios que consulten los mismos datos deberán ver los datos que existían antes del cambio. Una vez que el usuario guarde los datos, las nuevas consultas deberían revelar el nuevo valor de los datos.
Sincronización
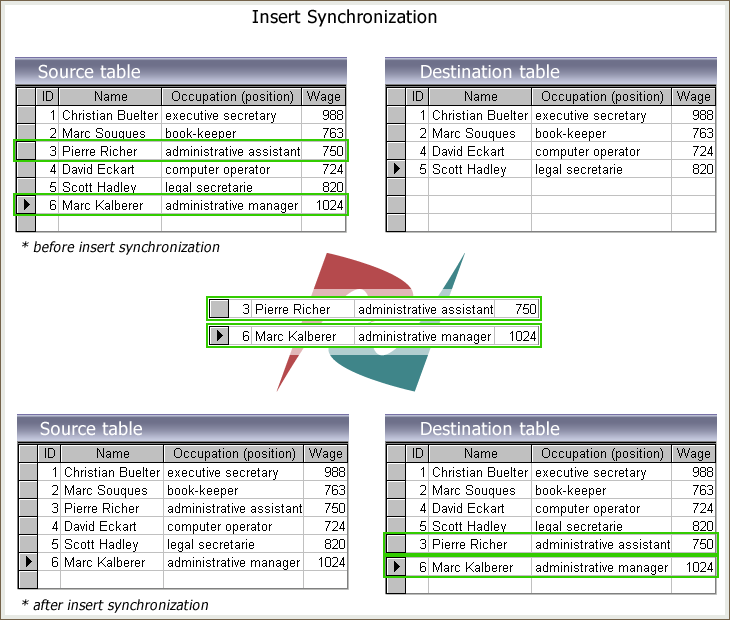
La sincronización de bases de datos establece la coherencia de los datos entre dos o más bases de datos, copiando automáticamente los cambios de ida y vuelta. La armonización de los datos a lo largo del tiempo debe realizarse de forma continua. La extracción de datos de la base de datos de origen (maestra) a la de destino (esclava) es el caso más trivial.
NOTA: La sincronización funciona sobre la base de la restricción de clave primaria. Las estructuras de las bases de datos deben contener una clave primaria o un índice único o primario, no uno compuesto.
Los nuevos registros de la tabla de origen se transferirán automáticamente a la de destino, en caso de que no haya registros apropiados en la tabla de destino con valores de clave primaria idénticos. Como resultado del proceso de sincronización de la base de datos, los registros ausentes se insertarán en las tablas de destino.
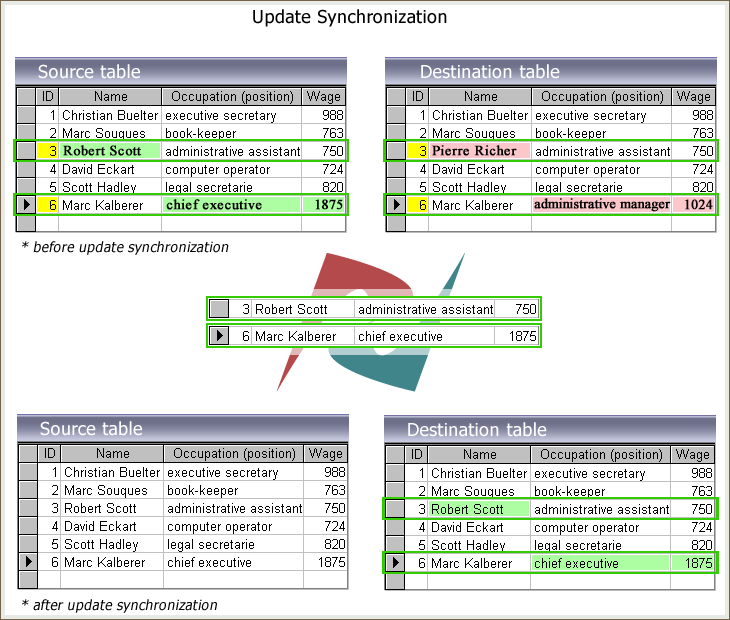
Cuando se producen cambios en la base de datos de origen, hay que realizar los cambios correspondientes en la base de datos de destino. El sincronizador compara primero los valores de los registros. A continuación, los registros modificados se sustituirán en las tablas de destino para establecer la identidad entre las dos tablas. Como resultado de la sincronización de las actualizaciones, todos los datos se mantienen actualizados.
Lock
Un bloqueo de base de datos se utiliza para "bloquear" algunos datos en una base de datos de manera que sólo un usuario/sesión de la base de datos pueda actualizar esos datos en particular. Así, los bloqueos de bases de datos existen para evitar que dos o más usuarios de la base de datos actualicen exactamente el mismo dato al mismo tiempo. Cuando los datos están bloqueados, eso significa que otra sesión de la base de datos NO puede actualizar esos datos hasta que se libere el bloqueo (lo que desbloquea los datos y permite a otros usuarios de la base de datos actualizar esos datos). Los bloqueos suelen liberarse mediante una sentencia SQL ROLLBACK o COMMIT.
Supongamos que la sesión A de la base de datos intenta actualizar algunos datos que ya están bloqueados por la sesión B de la base de datos. Bueno, la sesión A será colocada en lo que se llama un estado de espera de bloqueo, y la sesión A se detendrá de hacer más progreso con cualquier transacción SQL que esté realizando. Otra forma de decir esto es que la sesión A estará "estancada" hasta que la sesión B libere el bloqueo sobre esos datos.
Si una sesión termina esperando demasiado tiempo por algunos datos bloqueados, entonces algunas bases de datos, como DB2 de IBM, realmente se agotarán después de una cierta cantidad de tiempo y devolverán un error en lugar de esperar y luego actualizar los datos como se solicita. Pero algunas bases de datos, como Oracle, pueden manejar la situación de manera diferente - Oracle puede realmente dejar una sesión en un estado de espera de bloqueo por una cantidad indefinida de tiempo. Por lo tanto, hay muchas diferencias entre los distintos proveedores de bases de datos en cuanto a cómo deciden tratar los bloqueos y otras sesiones que esperan que se liberen los bloqueos.
Bloqueo a nivel de base de datos
Con los bloqueos a nivel de base de datos, toda la base de datos está bloqueada, lo que significa que sólo una sesión de la base de datos puede aplicar cualquier actualización a la base de datos. Este tipo de bloqueo no se utiliza a menudo, porque obviamente impide que todos los usuarios, excepto uno, actualicen algo en la base de datos. Sin embargo, este bloqueo puede ser útil cuando es necesaria alguna actualización de soporte importante - como la actualización de la base de datos a una nueva versión del software. Oracle tiene un modo exclusivo, que se utiliza para permitir que sólo una sesión de usuario utilice la base de datos - esto es básicamente un bloqueo de la base de datos.
Bloqueo a nivel de archivo
Con un nivel de bloqueo de archivo, se bloquea todo un archivo de la base de datos. ¿Qué es exactamente un archivo en una base de datos? Bueno, un archivo puede tener una gran variedad de datos - dentro de un archivo puede haber una tabla entera, una parte de una tabla, o incluso partes de diferentes tablas. Debido a la variedad de datos almacenados dentro de un archivo, este tipo de nivel de bloqueo es menos favorecido.
Bloqueo a nivel de tabla
Un bloqueo a nivel de tabla es bastante sencillo: significa que una tabla entera está bloqueada en su totalidad. Este nivel de bloqueo es útil cuando se realiza un cambio que afecta a toda una tabla, como la actualización de todas las filas de una tabla, o la modificación de la tabla para añadir o eliminar columnas. En Oracle, esto se conoce como bloqueo DDL, porque se utiliza con las sentencias DDL (Data Definition Language) como CREATE, ALTER y DROP - básicamente sentencias que modifican toda la tabla de una forma u otra.
Bloqueo a nivel de columna
Un bloqueo a nivel de columna sólo significa que algunas columnas dentro de una fila dada en una tabla dada están bloqueadas. Esta forma de bloqueo no se utiliza habitualmente porque requiere muchos recursos para activar y liberar bloqueos a este nivel. Además, la mayoría de los proveedores de bases de datos ofrecen muy poco soporte para el bloqueo a nivel de columna.
Bloqueo a nivel de fila
Un bloqueo a nivel de fila se aplica a una fila de una tabla. Este es también el nivel de bloqueo más común, y prácticamente todos los principales proveedores de bases de datos soportan los bloqueos a nivel de fila.
¿Los bloqueos son utilizados automáticamente por las bases de datos?
Cuando los datos se borran o se actualizan, los bloqueos se utilizan siempre, aunque el usuario de la base de datos no escriba su SQL para indicar explícitamente que se debe utilizar un bloqueo. Muchos de los RDBMS que existen hoy en día también tienen soporte para utilizar la cláusula "FOR UPDATE OF" combinada con una sentencia SELECT normal. La cláusula FOR UPDATE OF básicamente dice que el usuario de la base de datos tiene la intención de actualizar algunos datos - aunque el usuario de la base de datos tampoco está obligado a hacer cambios en esos datos en particular. Y, como se declara la intención de actualizar los datos, significa que también se colocará un bloqueo en esos datos.
Deadlock
En una base de datos, un bloqueo es una situación no deseada en la que dos o más transacciones esperan indefinidamente a que la otra ceda los bloqueos. Se dice que el bloqueo es una de las complicaciones más temidas en los SGBD, ya que hace que todo el sistema se detenga.
Ejemplo - Vamos a entender el concepto de Deadlock con un ejemplo:
Supongamos que la transacción T1 mantiene un bloqueo en algunas filas de la tabla Estudiantes y necesita actualizar algunas filas de la tabla Calificaciones. Simultáneamente, la transacción T2 tiene bloqueos en esas mismas filas (que T1 necesita actualizar) en la tabla Grades pero necesita actualizar las filas de la tabla Student que tiene la transacción T1.
Ahora surge el principal problema. La transacción T1 esperará a que la transacción T2 ceda el bloqueo, y de forma similar, la transacción T2 esperará a que la transacción T1 ceda el bloqueo. Como consecuencia, toda la actividad se detiene y permanece parada para siempre a menos que el SGBD detecte el bloqueo y aborte una de las transacciones.

Evitar el bloqueo
Cuando una base de datos está atascada en un punto muerto, siempre es mejor evitar el punto muerto en lugar de reiniciar o abortar la base de datos. El método para evitar el bloqueo es adecuado para bases de datos pequeñas, mientras que el método para prevenir el bloqueo es adecuado para bases de datos más grandes.
Un método para evitar el bloqueo es el uso de una lógica consistente con la aplicación. En el ejemplo anterior, las transacciones que acceden a los estudiantes y a las calificaciones deben acceder siempre a las tablas en el mismo orden. De este modo, en el escenario descrito anteriormente, la transacción T1 simplemente espera a que la transacción T2 libere el bloqueo en Grados antes de comenzar. Cuando la transacción T2 libera el bloqueo, la transacción T1 puede proceder libremente.
Otro método para evitar el bloqueo es aplicar tanto el mecanismo de bloqueo a nivel de fila como el nivel de aislamiento READ COMMITTED. Sin embargo, esto no garantiza la eliminación completa de los bloqueos.
Prevención de bloqueos
Para una base de datos grande, el método de prevención de bloqueos es adecuado. Se puede evitar un bloqueo si los recursos se asignan de tal manera que nunca se produzca un bloqueo. El SGBD analiza las operaciones para ver si pueden crear una situación de bloqueo o no, y si lo hacen, nunca se permite la ejecución de esa transacción.
Sonríe Yahshua te ama



Comentarios
Publicar un comentario