Bases de Datos Distribuidas
¿Qué es una base de datos distribuida?
Una base de datos distribuida consiste en dos o más archivos ubicados en diferentes sitios, ya sea en la misma red o en redes completamente diferentes. Algunas partes de la base de datos se almacenan en varias ubicaciones físicas y el procesamiento se distribuye entre varios nodos de la base de datos. Un sistema de gestión de bases de datos distribuidas centralizado (DDBMS) integra los datos de forma lógica para que puedan ser gestionados como si estuvieran todos almacenados en la misma ubicación.
El DDBMS sincroniza todos los datos periódicamente y garantiza que las actualizaciones y eliminaciones de datos realizadas en una ubicación se reflejen automáticamente en los datos almacenados en otra. Por el contrario, una base de datos centralizada consiste en un único archivo de base de datos ubicado en un sitio utilizando una única red.
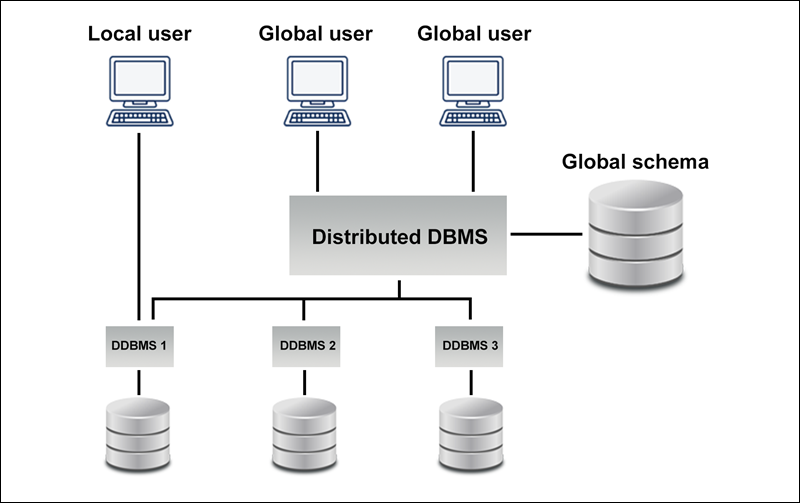
Cuando se encuentran en una colección, las bases de datos distribuidas están lógicamente interrelacionadas entre sí, y a menudo representan una única base de datos lógica. Con las bases de datos distribuidas, los datos se almacenan físicamente en varios sitios y se gestionan de forma independiente. Los procesadores de cada sitio están conectados por una red, y no tienen ninguna configuración de multiprocesamiento. Un error común es pensar que una base de datos distribuida es un sistema de archivos poco conectado. En realidad, es mucho más complicado que eso. Las bases de datos distribuidas incorporan el procesamiento de transacciones, pero no son sinónimo de sistemas de procesamiento de transacciones.
¿En que consiste la Replicación de Datos?
La replicación de datos es el proceso de almacenamiento de datos en más de un sitio o nodo. Es útil para mejorar la disponibilidad de los datos. Se trata simplemente de copiar los datos de una base de datos de un servidor a otro para que todos los usuarios puedan compartir los mismos datos sin ninguna incoherencia. El resultado es una base de datos distribuida en la que los usuarios pueden acceder a los datos relevantes para sus tareas sin interferir en el trabajo de los demás.
La replicación de datos abarca la duplicación de las transacciones de forma continua, de manera que la réplica se encuentra en un estado constantemente actualizado y sincronizado con la fuente. Sin embargo, en la replicación de datos los datos están disponibles en diferentes lugares, pero una relación particular tiene que residir en un solo lugar. Puede haber una replicación completa, en la que toda la base de datos se almacena en cada sitio.
También puede haber una replicación parcial, en la que algunos fragmentos de la base de datos utilizados con frecuencia se replican y otros no.
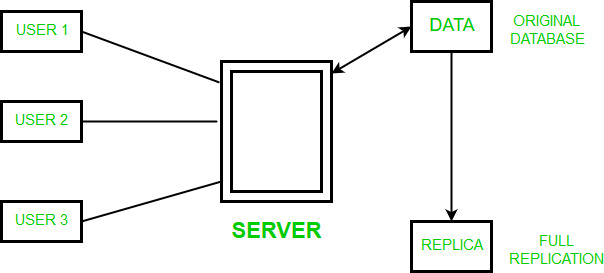
Tipos de replicación de datos -
Replicación Transaccional - En la replicación transaccional los usuarios reciben copias iniciales completas de la base de datos y luego reciben actualizaciones a medida que los datos cambian. Los datos se copian en tiempo real desde el editor a la base de datos receptora (suscriptor) en el mismo orden en que se producen con el editor, por lo que en este tipo de replicación se garantiza la consistencia transaccional. La replicación transaccional se utiliza normalmente en entornos de servidor a servidor. No se limita a copiar los cambios de datos, sino que replica cada cambio de forma consistente y precisa.
Replicación de instantáneas - La replicación de instantáneas distribuye los datos exactamente como aparecen en un momento específico en el tiempo no supervisa las actualizaciones de los datos. Se genera la instantánea completa y se envía a los usuarios. La replicación instantánea se utiliza generalmente cuando los cambios de datos son poco frecuentes. Es un poco más lenta que la transaccional porque en cada intento mueve múltiples registros de un extremo a otro. La replicación instantánea es una buena manera de realizar la sincronización inicial entre el editor y el suscriptor.
Replicación por fusión - Los datos de dos o más bases de datos se combinan en una sola base de datos. La replicación combinada es el tipo de replicación más complejo porque permite que tanto el editor como el suscriptor realicen cambios en la base de datos de forma independiente. La replicación combinada se utiliza normalmente en entornos de servidor a cliente. Permite enviar los cambios de un editor a varios suscriptores.
¿Qué es el proceso de Consignación de dos Fases ?
Un commit de dos fases es un protocolo estandarizado que garantiza la implementación de un commit de base de datos en la situación en la que una operación de commit debe dividirse en dos partes separadas. En la gestión de bases de datos, guardar los cambios de datos se conoce como commit y deshacer los cambios se conoce como rollback. Ambas cosas pueden lograrse fácilmente utilizando el registro de transacciones cuando se trata de un único servidor, pero cuando los datos están repartidos por servidores geográficamente diversos en la informática distribuida (es decir, cada servidor es una entidad independiente con registros de registro separados), el proceso puede resultar más complicado.
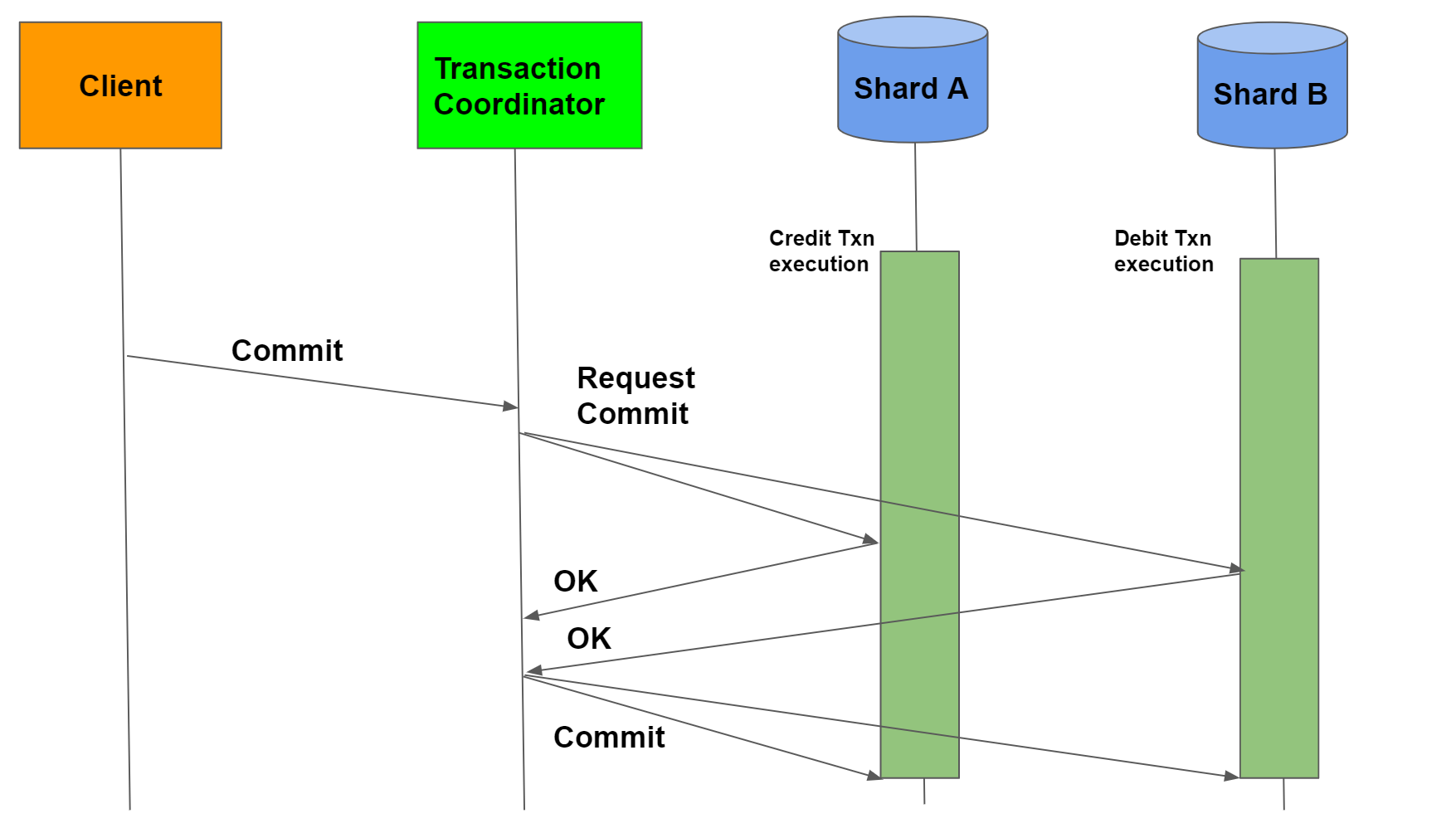
Un objeto especial, conocido como coordinador, es necesario en una transacción distribuida. Como su nombre indica, el coordinador organiza las actividades y la sincronización entre los servidores distribuidos. El commit en dos fases se implementa de la siguiente manera:
Fase 1 - Cada servidor que necesita consignar datos escribe sus registros de datos en el registro. Si un servidor no tiene éxito, responde con un mensaje de fallo. Si tiene éxito, el servidor responde con un mensaje de OK.
Fase 2 - Esta fase comienza después de que todos los participantes respondan OK. Entonces, el coordinador envía una señal a cada servidor con instrucciones de confirmación. Después de la confirmación, cada uno de ellos escribe la confirmación como parte de su registro de bitácora para referencia y envía al coordinador un mensaje de que su confirmación se ha implementado con éxito. Si un servidor falla, el coordinador envía instrucciones a todos los servidores para revertir la transacción. Después de que los servidores retrocedan, cada uno de ellos envía un mensaje indicando que la transacción se ha completado.
¿Qué es DATA WAREHOUSE ?
Un almacén de datos (DW) es un proceso de recogida y gestión de datos procedentes de diversas fuentes para proporcionar información empresarial significativa. Un almacén de datos se utiliza normalmente para conectar y analizar los datos empresariales procedentes de fuentes heterogéneas. El almacén de datos es el núcleo del sistema de BI que se construye para el análisis de datos y la elaboración de informes.
Es una mezcla de tecnologías y componentes que ayuda al uso estratégico de los datos. Es el almacenamiento electrónico de una gran cantidad de información por parte de una empresa que está diseñada para la consulta y el análisis en lugar del procesamiento de transacciones. Es un proceso de transformación de datos en información y de puesta a disposición de los usuarios en el momento oportuno para marcar la diferencia.

La base de datos de apoyo a la toma de decisiones (Data Warehouse) se mantiene separada de la base de datos operativa de la organización. Sin embargo, el almacén de datos no es un producto sino un entorno. Es una construcción arquitectónica de un sistema de información que proporciona a los usuarios información actual e histórica de apoyo a la toma de decisiones a la que es difícil acceder o presentar en el almacén de datos operativo tradicional. Muchos saben que una base de datos diseñada en 3NF para un sistema de inventario tiene muchas tablas relacionadas entre sí.
Por ejemplo, un informe sobre información de inventario actual puede incluir más de 12 condiciones unidas. Esto puede ralentizar rápidamente el tiempo de respuesta de la consulta y el informe. Un almacén de datos proporciona un nuevo diseño que puede ayudar a reducir el tiempo de respuesta y ayuda a mejorar el rendimiento de las consultas para informes y análisis.
El Datawarehouse beneficia a los usuarios para comprender y mejorar el rendimiento de su organización. La necesidad de almacenar datos evolucionó a medida que los sistemas informáticos se hicieron más complejos y necesitaron manejar cantidades cada vez mayores de información. Sin embargo, el Data Warehousing no es algo nuevo.
Sonríe Yahshua te ama



Comentarios
Publicar un comentario